동기
기존 연구는 데이터 센터에 데이터를 업로드하고 학습을 계속합니다.
모바일 데이터의 경우 데이터센터에서 학습을 하면 프라이버시 문제 발생 + 데이터 양에 비례해 비용이 증가한다.
정당성

여러 클라이언트와 중앙 서버가 함께 작동하여 분산된 데이터 상태에서 글로벌 모델을 교육하는 기술입니다.
로컬 클라이언트에서 모델을 교육한 후 모델 매개변수가 서버로 전송되고 단일 모델로 집계됩니다.
중앙 서버는 데이터가 없더라도 데이터로 모델을 훈련시킬 수 있습니다.
장점
– 네트워크를 통해 전송되지 않으므로 데이터 유출 위험 감소
– 클라이언트와 중앙 서버 간의 통신 비용 절감
특성
– non-IID(Independent and Idenically Distributed): 각 개인(클라이언트)이 사용하는 모바일 기기를 기반으로 하므로 인구분포를 특정인의 데이터로 표현할 수 없다.
– 불균형: 개인이 소유한 로컬 데이터의 양이 다름
– 대규모 분산형: 스마트폰과 같은 에지 장치를 학습시킬 수 있기 때문에 많은 고객 데이터를 처리할 수 있습니다.
연산

1. 서버에서 기본 모델 준비
2. K 고객으로부터, (효율성을 위해) 임의로 m을 선택하고 메인 모델을 서버로 보냅니다.
3. 각 클라이언트 내에서 기본 모델은 클라이언트의 로컬 데이터를 사용하여 학습됩니다.
4. 결과 무게를 다시 서버로 전송
5. 이렇게 수집된 가중치의 가중평균을 취하여 서버에서 모델을 업데이트합니다. (가중평균 : 각 고객이 보유하고 있는 데이터의 양만큼)
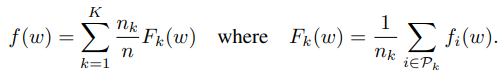
응용 분야
1. Google 키보드 추천 알고리즘 개선: Gboard
gboard가 추천 검색어를 표시하면 휴대전화는 추천 검색어를 클릭했는지 여부에 대한 정보를 로컬에 저장합니다. 연합 학습은 기기 내 레코드를 처리하여 gboard 쿼리 제안 모델의 다음 반복을 위한 개선 사항을 제안합니다.
2. 차량 네트워크
다음과 같은 차량 내 장치에서 생성된 데이터 GPS로 감지한 위치와 방향, 차량에 장착된 카메라로 촬영한 영상, 유압 센서로 얻은 압력 데이터를 자동차 제조사에서 활용해 지능형 내비게이션 서비스 제공 => 기차
3. 의료 시스템
환자의 비밀정보를 노출하지 않고 교육이 가능합니다.
분산 학습 대 연합 학습
| 분산 학습 | 제휴 학습 |
| 단일 날짜 머신/데이터 센터(예: 서버) 학습을 계속합니다. (중앙 집중식 네트워크) | 모바일/IoT 기기를 주로 취급 현지의 환경에서 학습. (탈중앙화 네트워크) |
| 데이터가 데이터 센터(서버)에 저장되어 있고 데이터가 고르게 분포되어 있다고 가정(ID) → 데이터 셔플 | 일반적으로 각 클라이언트의 로컬 데이터는 서로 독립적입니다. (비 IID) |
| 네트워크에 연결된 모든 클라이언트는 언제든지 개인 정보에 액세스하고 검토할 수 있습니다. | 각 고객의 개인 정보는 보호됩니다. |
| 계산하다 비용에 집중 | 의사소통 비용에 집중 |
원하는 방식으로 연합 학습 구성
연합 학습: 분산된 데이터 환경에서 여러 로컬 클라이언트와 중앙 서버가 함께 작동하여 글로벌 모델을 학습하는 기술입니다. 대부분의 DL/ML 모델은 빅 데이터를 기반으로 합니다.
at0z.tistory.com
https://velog.io/@tjdcjffff/Federated-Learning
제휴 학습
오늘 연합 학습에 대해 간단히 살펴보겠습니다. 모바일 장치가 더욱 중요해짐에 따라 딥 러닝과 모바일 장치를 결합한 애플리케이션이 개발되고 있습니다. 모바일 장치의 예는 다음과 같습니다. Se
velog.io